
기본 타입(Basic types)
이 절에서는 기본 내장 타입과, 이들에 대해 사용 가능한 연산들을 자세히 다룹니다.
Booleans (불리언)
Nim의 불리언 타입은 `bool`이며, 미리 정의된 값 true와 false로 구성됩니다.
`while`, `if`, `elif`, `when` 문에서 조건식은 반드시 bool 타입이어야 합니다.
불리언 타입에는 `not, and, or, xor, <, <=, >, >=, !=, ==` 연산자가 정의되어 있습니다.
`and`와 `or` 연산자는 단락 평가(short-circuit evaluation)를 수행합니다. 예:
```nim
while p != nil and p.name != "xyz":
# p == nil일 경우 p.name은 평가되지 않음
p = p.next
```
Characters (문자)
문자 타입은 `char`입니다. 크기는 항상 1바이트이며, 대부분의 UTF-8 문자를 직접 표현할 수는 없지만, 멀티바이트 UTF-8 문자를 구성하는 바이트 중 하나는 표현할 수 있습니다.
이러한 설계는 효율성 때문입니다. 대부분의 경우, UTF-8은 원래 멀티바이트 처리에 맞게 설계되었기 때문에 프로그램은 여전히 UTF-8을 올바르게 다룰 수 있습니다.
- 문자 리터럴은 작은따옴표(`'a'`)로 둘러쌉니다.
- `==, <, <=, >, >=` 연산자를 사용할 수 있습니다.
- `$` 연산자는 `char`를 `string`으로 변환합니다.
- `char`와 정수는 혼합할 수 없습니다.
- 문자 코드 값을 얻으려면 `ord` proc을 사용합니다.
- 정수에서 문자로 변환하려면 `chr` proc을 사용합니다.

Strings (문자열)
문자열(string) 변수는 mutable(변경 가능)므로 문자열에 덧붙이기가 가능하며 효율적입니다.
- Nim의 문자열은 널 종료(zero-terminated)와 길이 필드(length field)를 동시에 가집니다.
- 문자열의 길이는 내장된 `len` proc으로 가져올 수 있으며, 여기에는 종료 널(`\0`)은 포함되지 않습니다.
- 종료 널에 접근하는 것은 오류입니다. 종료 널은 단지 Nim 문자열을 `cstring`으로 변환할 때 복사 없이 사용할 수 있도록 존재합니다.
문자열 대입은 복사(copy)를 수행합니다.
- `&` 연산자는 문자열을 연결(concatenate)합니다.
- `add`를 사용하여 문자열을 덧붙일(append) 수도 있습니다.
문자열은 사전식(lexicographical) 순서로 비교되며, 모든 비교 연산자를 지원합니다.
관례적으로 문자열은 UTF-8 인코딩을 따른다고 가정하지만, 강제되지는 않습니다. 예를 들어, 바이너리 파일에서 읽어들인 문자열은 단순한 바이트 시퀀스일 뿐입니다.
인덱스 연산 `s[i]`는 문자열 `s`의 i번째 char를 의미합니다. 이는 i번째 unichar가 아닙니다.
문자열 변수는 기본적으로 빈 문자열 `""`로 초기화됩니다.
unichar란?
UTF-8에서는 2~4바이트 크기의 문자들이 있습니다. 한글이나 한자가 여기에 포함되죠. 한글의 경우 3개의 바이트 시퀀스로 표현됩니다. 그래서 컴퓨터는 한글을 3개의 `char`로 인식합니다. 반면, 우리가 인식하는 문자 1개는 grapheme이라고 합니다. UTF-8 문자의 값을 압축적으로 하나의 정수로 표현하는 방식이 있는데, 이를 코드포인트(codepoint)라고 합니다. 즉, 3바이트의 정보가 모두 녹아들어있는 정수값인 거죠. 이러한 코드포인트를 Nim 1.0에서는 `unichar`라고 불렀고, Nim 2.0에서는 `rune` type으로 표현합니다.
따라서 `s[i]`는 i번째 unichar가 아니라, i번째 char라는 말은, 인덱싱 연산자 `[]`를 사용해도 우리가 인식하는 grapheme의 단위로 출력되는 것이 아니고 1바이트 짜리의 문자 쪼가리가 출력된다는 의미입니다. 아래 예제코드의 마지막에 보면, 2글자(grapheme)의 "한글"이 6개로 쪼개져서 출력되며 폰트가 깨져서 표시도 제대로 되지 않는 것을 볼 수 있습니다. 한글 문자열을 다루기 아주 까다로울 것 같죠?
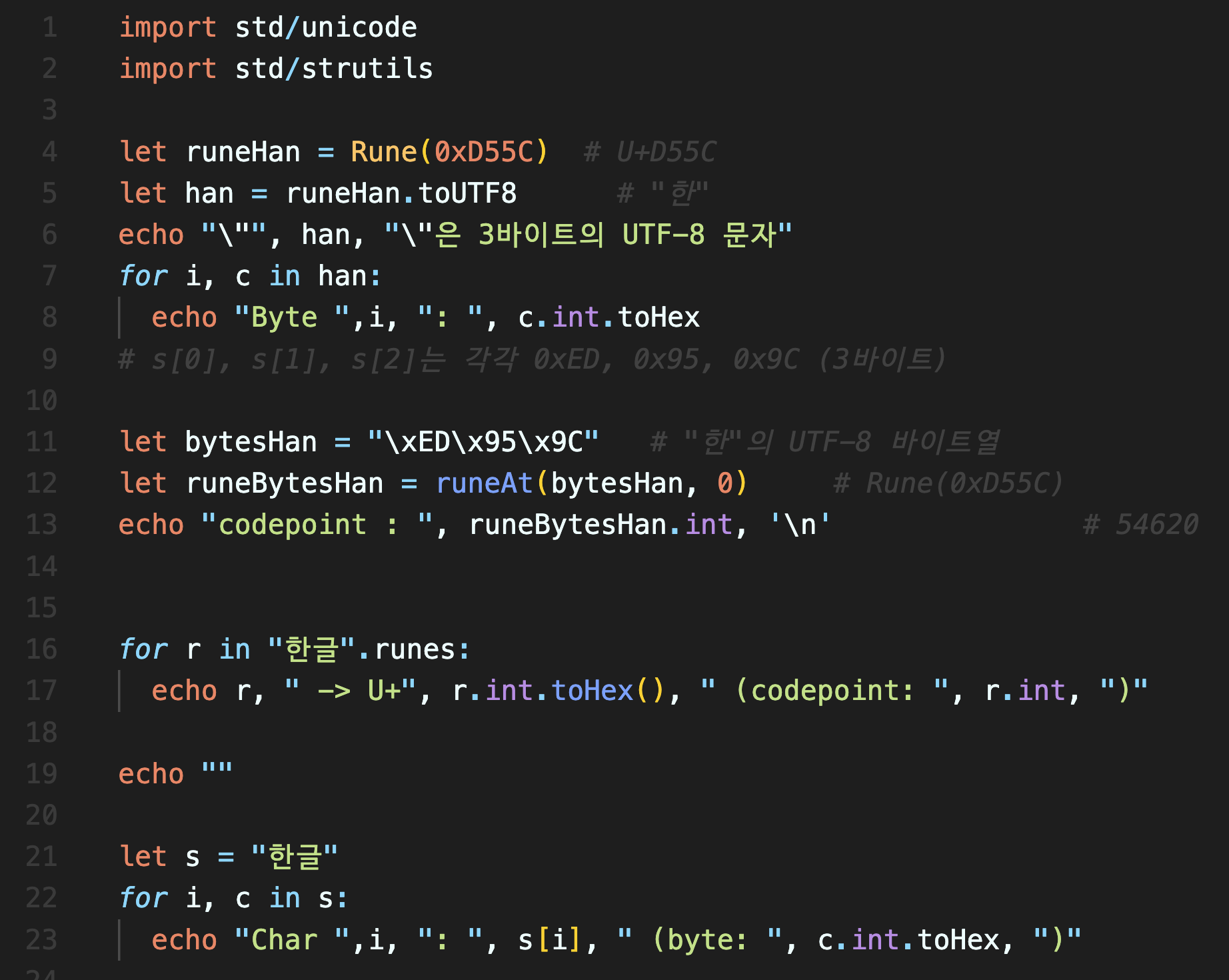
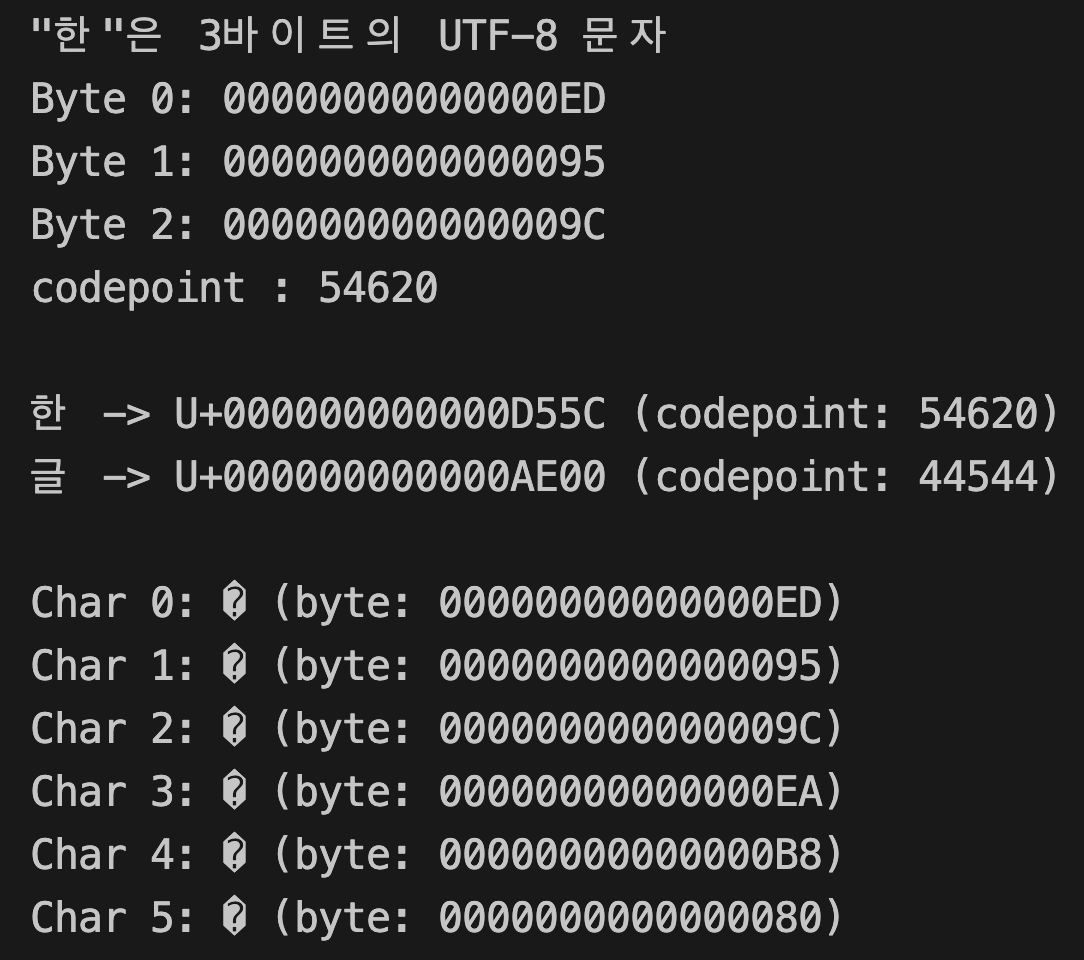
Integers (정수)
Nim에는 다음과 같은 정수 타입이 내장되어 있습니다:
`int int8 int16 int32 int64`
`uint uint8 uint16 uint32 uint64`
- 기본 정수 타입은 `int`입니다.
- 정수 리터럴은 타입 접미사(suffix)를 붙여 다른 타입을 지정할 수 있습니다:
```nim
let
x = 0 # x는 int
y = 0'i8 # y는 int8
z = 0'i32 # z는 int32
u = 0'u # u는 uint
```
- `int`의 크기는 포인터와 동일합니다(일반적으로 64bit). (메모리에 있는 객체를 세는 데 자주 사용되기 때문입니다.)
정수에는 `+ - * div mod < <= == != > >=` 연산자가 정의되어 있습니다.
또한 `and or xor not` 연산자는 비트 단위(bitwise) 연산을 수행합니다.
- 왼쪽 시프트: `shl`
- 오른쪽 시프트: `shr`
비트 시프트 연산자는 항상 피연산자를 unsigned로 처리합니다.
산술적 시프트가 필요하다면 일반 곱셈 또는 나눗셈을 사용하면 됩니다.
모든 unsigned 연산은 wrap around를 수행하며, 오버플로우나 언더플로우 오류를 발생시키지 않습니다.
정수 타입 간 혼합 연산에서는 손실 없는 자동 형 변환이 수행됩니다. 그러나 정보 손실이 발생할 수 있는 변환이라면, RangeDefect 예외가 발생합니다(컴파일 타임에 감지 불가능한 경우).
Floats (부동소수점)
Nim에는 다음 부동소수점 타입이 내장되어 있습니다:
`float float32 float64`
- 기본 부동소수점 타입은 `float`입니다.
- 현재 구현에서 `float`는 항상 64비트입니다.
부동소수점 리터럴에도 타입 접미사를 붙일 수 있습니다:
```nim
var
x = 0.0 # x는 float
y = 0.0'f32 # y는 float32
z = 0.0'f64 # z는 float64
```
부동소수점에는 `+ - * / < <= == != > >=` 연산자가 정의되어 있으며, IEEE-754 표준을 따릅니다.
- 서로 다른 크기의 부동소수점 타입이 섞여 있는 경우, 작은 타입이 큰 타입으로 자동 변환됩니다.
- 정수 타입은 자동으로 `float`으로 변환되지 않으며, `float`도 자동으로 정수로 변환되지 않습니다.
- 변환에는 `toInt`, `toFloat` proc을 사용해야 합니다.
Type Conversion (형 변환)
수치 타입 간 변환은 타입을 함수처럼 호출해서 수행합니다:
```nim
var
x: int32 = 1.int32 # int32(1)과 동일
y: int8 = int8('a') # 'a' == 97'i8
z: float = 2.5
sum: int = int(x) + int(y) + int(z) # sum == 100
```
본 설명은 Nim 공식 문서(https://nim-lang.org/docs/tut1.html, Creative Commons Attribution 3.0) 및 코드 예제(MIT License)를 바탕으로 하였습니다.
'Programming Languages > Nim' 카테고리의 다른 글
| [Nim 언어 강좌] Enum, ordinal types, subrange (0) | 2025.10.05 |
|---|---|
| [Nim 언어 강좌] 내부 타입 표현 (0) | 2025.10.04 |
| [Nim 언어 강좌] 이터레이터 (0) | 2025.10.02 |
| [Nim 언어 강좌] 프로시저(3) - 연산자, 전방 선언, 함수와 메서드 (0) | 2025.10.01 |
| [Nim 언어 강좌] 프로시저(2) - 명명된 인자, 기본값, 오버로딩 (0) | 2025.09.30 |